
Abstract
3D articulated objects modeling has long been a challenging problem, since it requires to capture both accurate surface geometries and semantically meaningful and spatially precise structures, parts, and joints. Existing methods heavily depend on training data from a limited set of handcrafted articulated object categories (e.g., cabinets and drawers), which restricts their ability to model a wide range of articulated objects in an open-vocabulary context. To address these limitations, we propose Articulate AnyMesh, an automated framework that is able to convert any rigid 3D mesh into its articulated counterpart in an open-vocabulary manner. Given a 3D mesh, our framework utilizes advanced Vision-Language Models and visual prompting techniques to extract semantic information, allowing for both the segmentation of object parts and the construction of functional joints. Our experiments show that Articulate AnyMesh can generate large-scale, high-quality 3D articulated objects, including tools, toys, mechanical devices, and vehicles, significantly expanding the coverage of existing 3D articulated object datasets. Additionally, we show that these generated assets can facilitate the acquisition of new articulated object manipulation skills in simulation, which can then be transferred to a real robotic system.
Overview
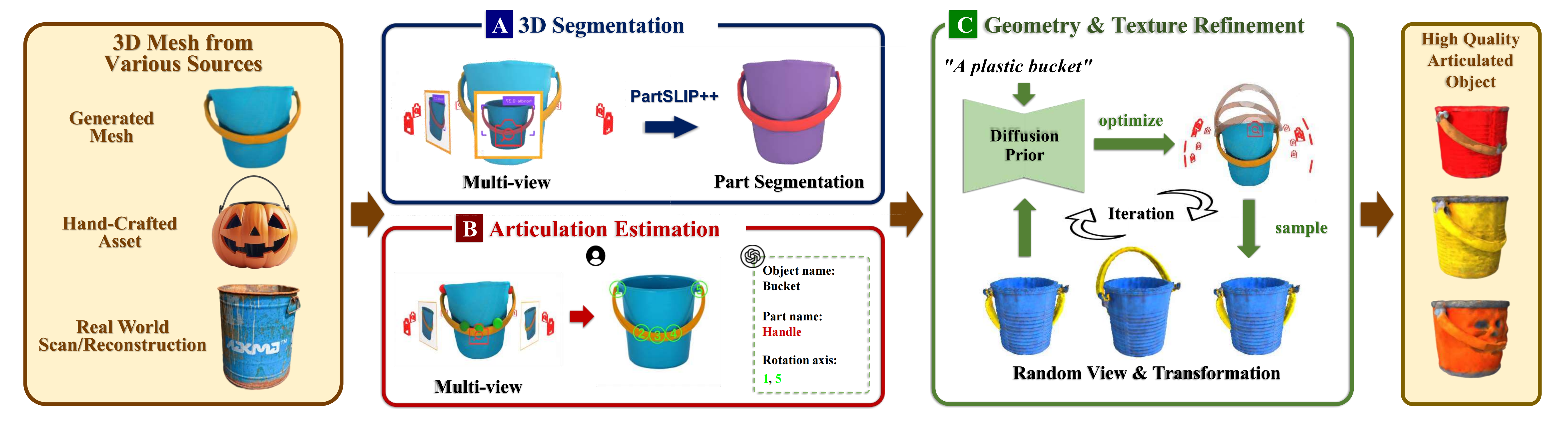
Our pipeline converts any mesh into its articulated counterpart, including hand-crafted meshes with part geometry, surface meshes generated through text-to-3D or image-to-3D methods and meshes reconstructed from real-world objects. The process involves three main steps:
- Movable Part Segmentation step employs the method proposed by PartSlip++ to segment movable parts from the input mesh.
- Articulation Estimation step extracts the articulation parameters for each movable part by leveraging geometric cues and prior knowledge from visual and language foundation models.
- Refinement step enhances the geometry and texture of the articulated object with geometry-aware 2D diffusion model Richdreamer, guided by SDS loss to distill the diffusion model's 3D prior.
Qualitative Results
Articulated objects annotated by Articulate AnyMesh, starting from an random 3D mesh.
Please select an example
Input 3D Object
Ouput Articulated Mesh
Articulated objects generated by Articulate AnyMesh, starting from an image-to-3D object
Please select an example
Input Image-to-3D Object
Output Articulated Mesh
Applications
Policy Learning
We follow DexArt for articulated object manipulation policy learning and evaluate two tasks: opening a laptop lid and lifting a bucket. We augment the training set for the bucket and laptop experiments, we include additional articulated objects of the same categories generated by Articulate AnyMesh.




Real-to-Sim-to-Real
We first reconstruct the 3D surface mesh of real-world objects using 2DGS. We then apply Articulate AnyMesh to convert the reconstructed mesh into an articulated object represented in URDF format, making it compatible with simulation environments. Next, we sample action targets and use motion planning to avoid collisions, generating a trajectory to successfully complete the task in simulation. Finally, we replicate the trajectory in the real world and observe that the robot arm can effectively execute the task.






BibTex
@article{qiu2025articulate,
title={Articulate AnyMesh: Open-vocabulary 3D Articulated Objects Modeling},
author={Qiu, Xiaowen and Yang, Jincheng and Wang, Yian and Chen, Zhehuan and Wang, Yufei and Wang, Tsun-Hsuan and Xian, Zhou and Gan, Chuang},
journal={arXiv preprint arXiv:2502.02590},
year={2025}
}